English
English Français
Français Español
Español Bahasa Indonesia
Bahasa Indonesia 中文 (中国)
中文 (中国) Русский
Русский Português
Português Deutsch
DeutschIf you ask someone for their favorite cat video, they’re unlikely to answer “oh LOL, the one on this server, at this sub-domain, under this file path, slash funny dash cat dot mp4”. Instead, they’ll most likely explain the video’s content: “oh haha, the one where the cat knocks the glass off the counter in gangsta style… amazing.”
Although this is an easy method for humans to think about content, it is not how we access content on the web today. Decentralized protocols like IPFS, on the other hand, use this form of content addressing to locate content on the decentralized web.
In this post, we’ll take a closer look at how this process works, looking under the hood to see what happens when you add a file to IPFS. While we’re at it, we’ll spend some time studying about IPLD, the Interplanetary File System’s underlying data format.
Fingerprinting
So, first and foremost, in order to allow content addressing, we must devise a method for creating a ‘fingerprint’ or description of the content that can be used to refer to it. We use ISBN numbers in the same way we do when looking for a book. In reality, cryptographic hashing functions are used to create fingerprints in web content addressing systems like IPFS.
To construct a digest, we take the raw content (in this case, a cat photo) and pass it through a hash function. This digest is cryptographically guaranteed to be unique to the contents of the file (or image, or whatever) and only that file. If I modify even a single bit in that file, the hash will be radically different.

So, now that we’ve worked out the image (made a digest), what’s next? What we’re looking for is a content address/identifier. So now we need to turn that digest into something that IPFS and other systems can utilize to find it… However, things aren’t as straightforward as they appear.
What if circumstances change in the future and we want to alter our approach to content? What if someone develops a more efficient hash function? Even the IP system we currently use has had to be upgraded. We’re sure the excellent people at IPFS have thought of it as well!
Multihashing
Have you ever noticed that all IPFS hashes begin with Qm? This is due to the fact that certain hashes are actually multihashes. This is amazing since the first two bytes of the multihash specify the hash algorithm was used and the length of the generated hash.
The first component in hex in most of our samples is 12, which indicates that this is the SHA256 hash algorithm, and the output length is 20 in hex (or 32 bytes), which is where we get the Qm when we base58 encode the whole thing. Then you could wonder why the whole thing is encoded in base58.
Because similar-looking letters like 0 (zero), O (capital o), I (capital I and l (lower case L) are deleted, as well as non-alphanumeric characters like + (plus) and / (slash), it becomes slightly more human readable. All of this is because we want a system that is future-proof and allows numerous fingerprinting technologies to coexist.
So, if that amazing new hashing function is invented, all we have to do is alter the first few bytes of the multihash, and we’re done… Qm is no longer the first character in IPFS hashes… However, because we’re using multihashes, the old ones will continue to function alongside the new ones… cool!
Merkle DAG ➞ IPLD
So, I’ve got my file, it’s hashed and encoded, and I’m ready to go. However, that isn’t the complete tale. What’s really going on is something like this…

The content is chunked into smaller sections (approximately 256k each), each component is hashed, and a CID is formed for each chunk. The chunks are then concatenated into a hierarchical data structure, for which a single, base CID is computed.
A Merkle DAG, or directed acyclic graph, is essentially what this data structure is.
Here’s a great video from Protocol Labs’ Juan Benet demonstrating how IPFS employs Merkle DAGs as its primary data structure… for the structure known as Interplanetary Linked Data (or IPLD):
Linked Data
Linked data is something that many in the decentralized web community have been discussing for a long time. Tim Berners-Lee has been working on it for a long time, and his new company, Solid, is making a profit out of it.
In essence, we’re talking about a framework that models everything as a collection of linked things. We have objects in the IPLD world, each containing Data and Links fields (where Data can be a small blob of unstructured, arbitrary binary data, and Links is an array of Link structures, which are simply links to other IPFS objects).

To that end, each link has a Name, a Hash (or CID) of the linked object, and a Size, which represents the linked object’s size. This last piece of information is only for the purpose of estimating object/file sizes without having to pre-fetch excessive amounts of data, but it’s highly useful to have.
IPLD (objects)
Data — blob of unstructured binary data of size < 256 kB.
Links — array of Link structures. These are links to other IPFS objects.
A Link structure has three data fields
Name — name of the Link
Hash — hash of the linked IPFS object
Size — cumulative size of linked IPFS object, including following its links
Learning by doing
Using the IPFS command line tools, we can really investigate IPLD objects. To begin, ensure that you have IPFS installed and are familiar with using the command line. Session 1 of our Textile Build Series is a good place to start if you need a refresher. We’ll take a quick look at the object structure for a different cat image whenever you’re ready (uses handy dandy jq tool). Begin by running the following command, which pipes (|) the IPFS object result to the jq command.
ipfs object get QmW2WQi7j6c7UgJTarActp7tDNikE4B2qXtFCfLPdsgaTQ | jq
Producing the following output:
{
“Links”: [
{
“Name”: “cat.jpg”,
“Hash”: “Qmd286K6pohQcTKYqnS1YhWrCiS4gz7Xi34sdwMe9USZ7u”,
“Size”: 443362
}
],
“Data”: “\b\u0001”
}
This object has a single Link, which we can investigate further with the same commands:
ipfs object get Qmd286K6pohQcTKYqnS1YhWrCiS4gz7Xi34sdwMe9USZ7u | jq
As a result, the following output is generated. It’s worth noting that the two Links are each about 256K in size:
{
“Links”: [
{
“Name”: “”,
“Hash”: “QmPEKipMh6LsXzvtLxunSPP7ZsBM8y9xQ2SQQwBXy5UY6e”,
“Size”: 262158
},
{
“Name”: “”,
“Hash”: “QmT8onRUfPgvkoPMdMvCHPYxh98iKCfFkBYM1ufYpnkHJn”,
“Size”: 181100
}
],
“Data”: “\b\u0002\u0018ކ\u001b ��\u0010 ކ\u000b”
}
This is very cool, and because DAGs (simple link-based graphs) are so flexible, we can use IPLD to represent almost any data structure. Let’s imagine you have the following directory structure and wanted to use IPFS to store it. First, it’s quite simple (see below), and second, the advantages of utilizing a DAG to represent data in IPFS are instantly evident, as we’ll see shortly.
test_dir/
├── bigfile.js
├── *hello.txt
└── my_dir
├── *my_file.txt
└── *testing.txt
In this example, assume that all three files with an asterisk (*) — hello.txt, my_file.txt, and testing.txx— contain the same text: “Hello World!/n”. Now let’s add them to IPFS:
ipfs add -r test_dir/
When you’re finished, you’ll have a DAG that looks like this:
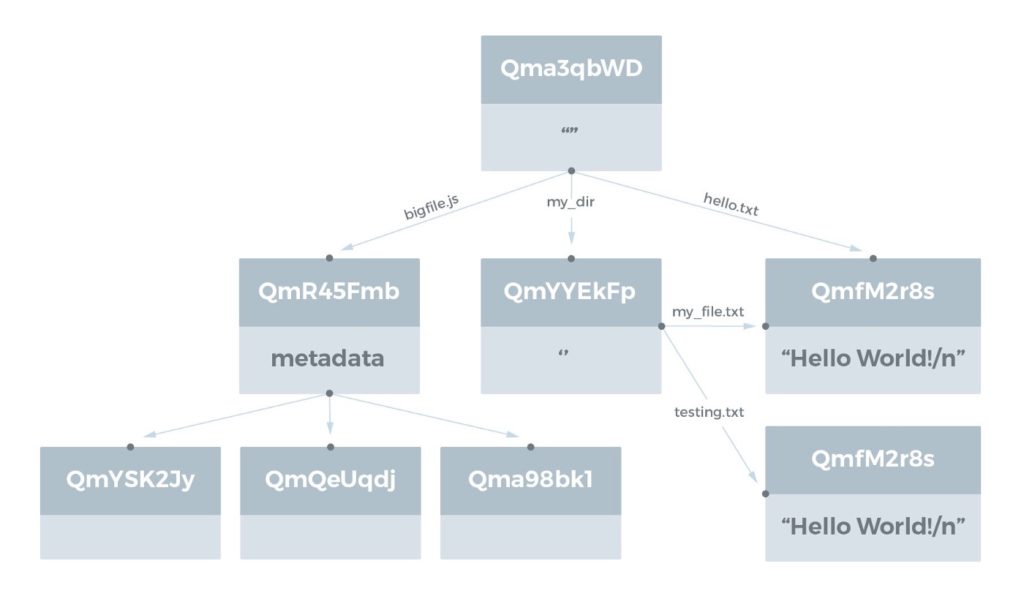
Where you end up with a sequence of objects linked by their CIDs (depending on the actual contents of the files in your directory). The actual folder is at the top level, without a name but with a CID. We can access bigfile.js, the underlying my dir, and hello.txt directly from there. We have links to my file.txt and testing.txt from my dir (in the center), which both lead to the same CID! This is a fantastic idea.
We receive deduplication ‘for free’ because we reference content rather than the files themselves! Finally, on the bottom left, we have bigfile.js, which has been divided into three smaller portions, each with its own CID, which when combined make the larger file. You receive a CID that explains the stuff below it if you follow all of these CIDs up the tree. This is an important notion…
Because we have Data and Links, our IPFS object collection has a graph-like structure (or a tree). DAG stands for Directed Acyclic Graph, while Merkle is named after the creator, Ralph Merkle, who developed hash trees in 1979. Anyway, Merkle DAGs provide content addressing, in which all information, including connections to items it refers, is uniquely recognized by its cryptographic hash.
Because all content is checked using its hash — proper hash, right content — the structure is tamper-proof. We don’t have any duplication because we’re hashing the contents of the files, because in the Merkle DAG universe, all objects with the same content are deemed equal (i.e. their hash values are the same), thus we only store them once. By design, there is no duplication.
We can experiment with Merkle DAGs and chunking up huge items directly from the command line. Let’s say we want to play with a good huge jpeg. If you like, you may ipfs cat it or just get it directly from GitHub:
ipfs cat QmWNj1pTSjbauDHpdyg5HQ26vYcNWnubg1JehmwAE9NnU9 > cosmos.jpg
Now you can add it locally, and if you cat’d it before, check sure the hashes match (here, the returned hash is assigned to the env variable hash):
hash=
ipfs add -q cosmos.jpg
echo $hash
You should receive a CID hash that is identical to this one (plus some progress):
QmWNj1pTSjbauDHpdyg5HQ26vYcNWnubg1JehmwAE9NnU9
Now let’s look at the underlying ipfs object for that specific image:
ipfs ls -v $hash
It’s worth noting that each linked object is around 256k in size. The image is made up of these parts when put together. So, when we ask the network for this file, we may actually request bits from other peers, and our peer will piece it all together at the end to give us the file we want. Decentralized to the core!
Hash Size Name
QmPHPs1P3JaWi53q5qqiNauPhiTqa3S1mbszcVPHKGNWRh 262158
QmPCuqUTNb21VDqtp5b8VsNzKEMtUsZCCVsEUBrjhERRSR 262158
QmS7zrNSHEt5GpcaKrwdbnv1nckBreUxWnLaV4qivjaNr3 262158
QmQQhY1syuqo9Sq6wLFAupHBEeqfB8jNnzYUSgZGARJrYa 76151
In addition, you may use this brand-new and entertaining tool to explore DAGs (IPLD objects) in the browser. For a fun example, look at the git example. Or, even better, investigate the DAG object shown above.
To demonstrate that the above four chunks do indeed make up the single image, use the following code to’manually’ connect the chunks together to produce the image file — this is essentially what cat is doing in the background when you refer to the base CID:
ipfs cat \
QmPHPs1P3JaWi53q5qqiNauPhiTqa3S1mbszcVPHKGNWRh \
QmPCuqUTNb21VDqtp5b8VsNzKEMtUsZCCVsEUBrjhERRSR \
QmS7zrNSHEt5GpcaKrwdbnv1nckBreUxWnLaV4qivjaNr3 \
QmQQhY1syuqo9Sq6wLFAupHBEeqfB8jNnzYUSgZGARJrYa \cat-cosmos.jpg
open cat-cosmos.jpg
Alternatively, you might use pipes to accomplish this more quickly:
ipfs refs $hash | ipfs cat > test.jpg ; open test.jpg
So there you have it. It’s all linked the whole way down. We’ve also learnt how to modify IPFS DAG objects using a variety of IPFS command-line tools. Handy!
Recap
So, let’s take a short look back. Merkle DAGs are at the heart of IPFS, but they’re also at the heart of git, bitcoin, dat, and a slew of other technologies. These DAGs are hash’trees’ made up of content blocks, each with its own hash. You can refer to any block within that tree, which implies you can make a tree out of any subblock combination.
Which takes us to another great feature of DAGs, especially when working with huge files: all you need is the base CID to reference a large data file, and you’ve got a confirmed reference to the entire object. Sending around CIDs and then requesting bits from numerous peers makes file sharing a snap for huge, popular files stored in multiple locations on a network, and means you only need to transfer a few bytes rather than the entire file.
However, you will seldom interface directly with DAGs or objects. Most of the time, your trusty ipfs add command will just generate the merkle DAG from data in files you supply, along with the underlying IPNS objects, and you’ll be OK. So, when you ask “what really happens when you add a file to IPFS?” the answer is cryptography, arithmetic, networking, and a little magic!
That’s all there is to it, guys. You now have a good understanding of what happens when you add a file to IPFS. What happens next will be the subject of a future blog entry. In the meantime, have a look at our other stories or join our Textile Photos waitlist to see what we’re working on using IPFS. While you’re at it, send us an email and tell us about your great distributed web projects— we’d love to hear about them!
Disclaimer: The opinion expressed here is not investment advice – it is provided for informational purposes only. It does not necessarily reflect the opinion of EGG Finance. Every investment and all trading involves risk, so you should always perform your own research prior to making decisions. We do not recommend investing money you cannot afford to lose.